
DC Blog
Learn how to keep your business, its staff and your devices protected with our free resources
-
Data Classification News
Data Residency & Custom Conditions
As it stands, Data Classification is a great way to help organisations manage their data. It enables IT and Compliance teams to move from a big set of unstructured unlabelled and unidentifiable content to a world where items can be catalogued by meta-data tags.
The benefits of this are many: Data Loss Prevention (DLP) is strengthened, Redundant Obsolete and Trivial (ROT) data can be identified and increasingly data which is governed by various regulations can be identified, making just about everyone’s life easier.
At HANDD we have started to group the different approaches to Data Classification techniques as Control Classifications – the traffic light technique. Descriptive Classification – tags being applied on top of the traffic lights. And Governance Classification which allows content to be identified as a type, enriched by descriptors, and then interpreted by controls.
This last type of classification lends itself to meeting data privacy and control legislation which is shaping the world we live in. Data Privacy analysts explain that these types of data privacy rules currently cover 25% of the world, perhaps even less. By the end of 2023 that will have tripled to 75% with lots of those have residency clauses inside them.
India, Australia and other countries are already drafting legislation which mandates that data concerning citizens of those countries should only be stored or processed within the country of origin. With the Covid pandemic and wider geo-political spectrum also being a factor, we’re expecting it to be a component in deploying and purchasing Data Classification technologies.
One of the more interesting ways of using Data Classification tools to address problems such as this is to utilise settings from machines and operating systems themselves rather than human beings. If we take a second to think about a modern device, be it a desktop, tablet or a mobile device, it has many indicators as to where in the world it is. These range from the simple things, like keyboard layout and time zone settings, to the geolocation settings recorded through the operating system about where on the planet the device is.
If we now need to label the origination point of the data, then our classification policies could do a lot worse than to start tapping into this readily available accurate location data.
The offerings from the HelpSystems stable are well placed to do this. Boldon James condition library allows querying the parameters in the OS to set these items quite nicely:
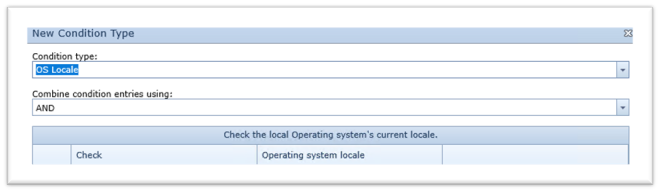
Completing the same in Titus requires a little more skill, but with their custom conditions and actions you’ve a lot more scope to solve the problem, providing you can turn your hand to a bit of .NET programming.
Using Visual Studio I authored a class which uses the online API ipinfo.io to discover amongst other interesting data, the country code of the machine being used. This is returned in JSON format which was then passed to Titus once I’d stripped out the bits I needed.
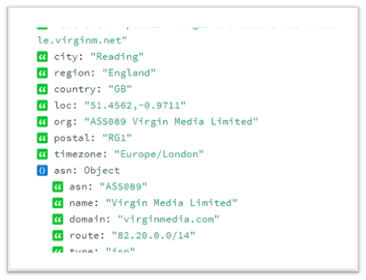
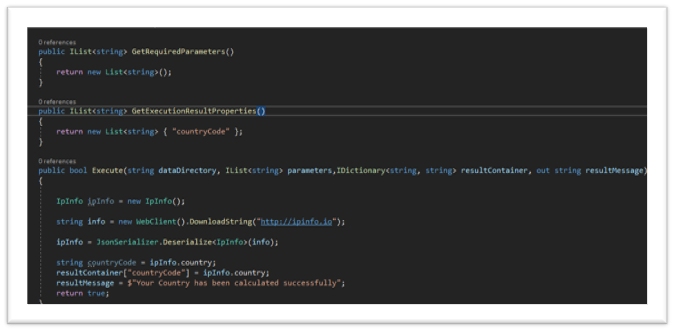
Once compiled the custom functions can be dropped into the Titus service and referenced in your policies.
Obviously, there’s a lot more you can achieve in .NET than just looking up your IP addresses and using custom conditions or actions within your policies is something which can make the difference between just labelling data and applying valuable insights into how that data should or could be used and controlled.
Every enterprise should be considering a Data Classification solution as a critical piece of their overall data protection strategy.
To learn more about the best-of-breed in the Data Classification market and what we can bring to the table, please contact us.

